
Understanding and Preventing Zero Day And Other Software Supply Chain Attacks
This is the second post in the series, intended to help better understand how third party risks can be managed, and addressing the problem of misinformation from high raking sources. Because of the pervasiveness of the myth that third party risks are unmanageable, primarily due to the insistence by insurance executives that “Well I don’t understand it, and therefore it can’t be done.” But because of this toxic insistence, it is necessary to break things down and provide detailed supporting information.
In this post, we will look at zero days and unpatched vulnerabilities as a type of exposure to third party risk. Zero days are similar to supply chain attacks, and many of the same methods for controlling zero days apply to supply chain attacks as well. MOVEit is an example of a zero day attack, which caused massive damage to the US and global economy. It illustrates exactly how these attacks work.
In some ways, it was the kind of systemic attack that insurers are constantly complaining about. However, it also illustrates all the ways the damage could have been prevented. MOVEit was bad, but it was also tragic, because so much of the loss could have been prevented, if we had our act together on this.
Manage Third Party Risk Through Critical Patch and Zero Day Management:
One of the biggest unnecessary losses that we continue to suffer is that of unpatched soſtware, which as been exploited and is actively being used to attack businesses. The principle is not hard to understand: soſtware sometimes has flaws discovered in it, and those flaws may make the soſtware subject to compromise. If this is the case, and the soſtware is high risk then moments matter. Mitigating steps must be taken right away, and these can include patching the soſtware or, if necessary, suspending its use until it can be safety returned to service.
A ”Zero day” is a situation where there are zero days of notice on a critical flaw, because the bad guys discover it first and the first sign of trouble is that you are breached by a novel flaw that was previously unknown and therefore could not be avoided. While this can happen, it should be noted that it would be astronomically bad luck to be hit on the literal first day an exploit is discovered and few organizations truly are.
Last summer, the world suffered the single most costly and damaging supply chain attack in history. The aſtermath is still not fully clear. Hundreds of companies were hacked and some of the most sensitive, highly damaging and private information is now in the hands of some of the most viscous ransomware gangs out there. The attack pumped over a quarter billion dollars of ransom into the Kl0p group, with some of it ending up with affiliates in Iran and North Korea. The attack has leſt the US and allies with a gaping wound torn open. The ransomware gangs now have the single largest injection of cash in their history, and much of it is already being used to buy weapons for the pro-Russia Ukrainian groups in the Donbas region.
MOVEit: A Textbook Example of What We Are Doing Wrong
The problem started with a product called MOVEit. MOVEIt is a secure server made by Progress soſtware. It is used in the highest security environments as a way of transferring high risk files between locations. For example, if a medical or financial institution needed to provide off-site access to secret files, MOVEit would be a natural choice to use, and thousands of customers use if for just that. As such, some of the most secure and sensitive environments rely on MOVEit. One would expect that such a product would be the subject to the highest levels of security testing and certification, but that is oſten not the case, due to poor enforcement and lax standards.

On May 27, 2023, it was discovered that the MOVEit server could easily be breached by an outsider through a simple method known as code injection. Code injection simply means that a command could be entered into the fields for things like login or password. If, instead of entering a login, a user entered a command to the system, the command would be run, allowing the user to unlock the server completely and do as they pleased.
Code injection is a well known type of attack. The image to the leſt shows how a user might enter computer code into a password field with the intention of bypassing the passwords. Code injection has been around for decades. It’s normally the result of poor coding practice. It’s so well known and common that it is standard for it to be tested for when secure systems are evaluated. Unfortunately, because that is not enforced and there is no third party to hold anyone’s feet to the fire on it, code testing is rarely done and even when it is, external audits and assurance is very rare.
Almost as soon as the flaw was discovered, it was exploited. Exploiting it was easy. MOVEit servers frequently face the internet and are as easy as using Google to find. Using other search methods, the Kl0p gang, a terrorist group aligned with the Russian far right and with affiliates in Afghanistan, Iran, Syria and North Korea began to exploit the MOVEit flaw. The first victims included the BBC, British Airlines and numerous other organizations in the US, UK and Canada. The attack started in the UK but within days, servers were being breached on both sides of the Atlantic.
At this point no further breach should have happened, because by end the of May, word had gotten out and a patch to fix the problem. Every breach that happened aſter the patch was issued and news dispatched as an act of extreme negligence.
Before the end of June, beaches at United Healthcare, Johns Hopkins University, Virgin, Aon, Prudential, Shell and others had leaked the private information of hundreds of millions of people, cost the world billions of dollars and enriched Russian terrorists beyond their wildest dreams. The hacks kept coming over the summer. The Kl0p gang even laughed, because as commentators talked about the situation on the news, nobody seemed to realize that the solution was pretty simple: track down the users of the soſtware and make them patch it.
In General, Attentive Companies Can Protect Themselves
It is important to note that few zero day hacks actually happen on the first day of the hack being discovered. That’s only true for some very unlucky organizations. From an underwriters perspective, there is a need to be certain that a broad variety of clients are covered, but for individual organizations, the problem can be greatly mitigated by simply engaging in the best practices of patch management.
Patch management is the process of updating software, and it usually is not as critical as it is when a zero day is making the rounds, but it is always important. It can be largely automated, of course. Done properly, patch management could stop more than 90% of these problems. Future articles will describe the patch management process in greater detail.
Because patch management is a form of preventative maintenance, many organizations have a great deal of trouble making it a priority without an external stakeholder to lean on them about it.
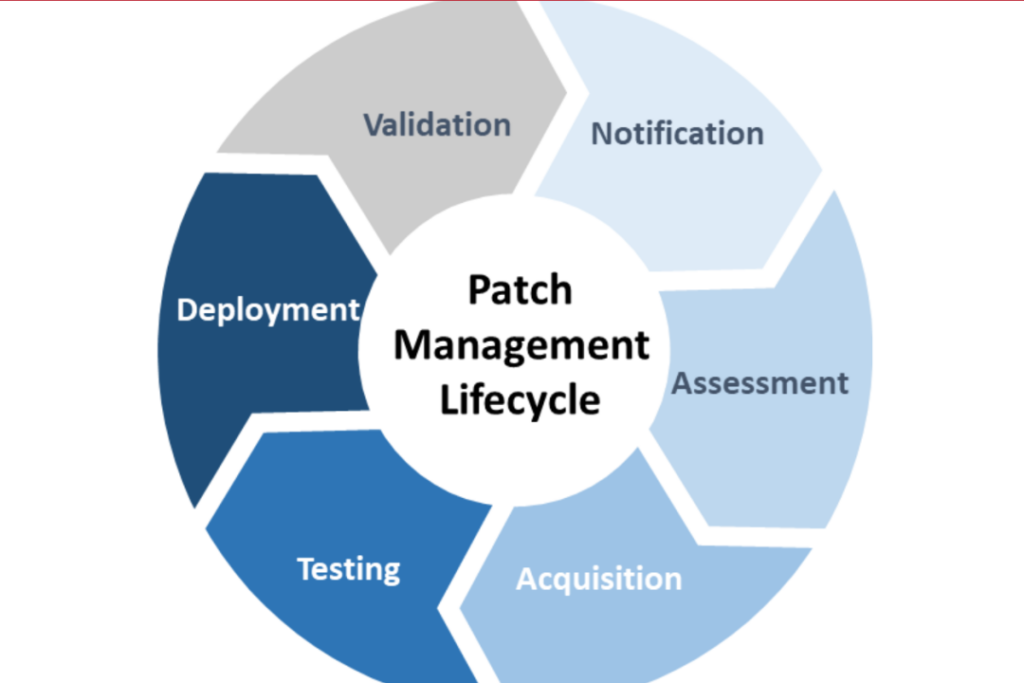
The Problem is a Lack of Infrastructure
Had MOVEit been a drug, there would have been a system of pharmacies, distributors and the FDA to coordinate a recall. Had MOVEit been a food product, the FDA, USDA and states would have sprung into action. Had MOVEit been a car, the state DMV’s along with auto dealerships and the DOT would have helped coordinate a recall. But MOVEit is soſtware, and unlike other products, there exists no system nor agency to coordinate a recall. Additionally, insurers have done nothing to establish any private sector effort to find and address soſtware or other third party products that may be producing a systemic loss.
In order to properly respond to these kind of events in the future, insurance companies need to start ahead of time by planning on how they will address a zero day emergency, such as what happened with MOVEit. Because only a small number of victims are attacked on the very first day, the overwhelming amount of damage that a soſtware based third party attack can cause can, in fact, be avoided. Doing so, however, requires a fast moving plan of action, because under these circumstances, every moment counts.
In fact, what needs to be done is very straight forward. Insurers must start by getting an inventory of their insured’s IT assets. An IT asset inventory is the first step in any kind of planning for a zero day emergency. This will help determine which clients have the soſtware in question. However, it is still necessary to provide notice to all, because there are circumstances where a product may not have been updated to the inventory. There are also times when technology can be used to scan systems looking for the vulnerable soſtware.
In many cases, this can itself be automated. Automated patch management systems do exist and many companies already use them. It is, however, important to verify that such systems are in place and test them regularly. In all cases, it is a best practice for human verification of the corrective action to be used in the highest risk circumstances
Once it is determined who uses the soſtware in question, it is simply a matter of assuring they are notified and that action is taken, either to patch the soſtware or to uninstall or disable it until a safer version is available. If companies already have a procedure in place to do so, this is a piece of cake, but as with anything else, it is not possible to do a good job when it is necessary to ad hoc a solution together at the last minute.
One reason it is important that the process move quickly is that with more exposure comes more risk that a system may have become compromised, even if it has not been detected. Therefore, as time goes on, the necessity of examining systems that were exposed for a significant period of time arises, making the entire process that much more costly and difficult.
Beyond the urgent zero day emergencies, having outreach to policyholders and assuring they are keeping their soſtware up to date is a good move to reduce risk in general. As a general rule, keeping soſtware up to date is a good way of reducing a broad number of risks, so doing so automatically and checking in with policyholders on this important issue has excellent ROI.
Further Mitigation:
As mentioned, organizations that were proactive in their patch management were likely to avoid all losses in the MOVEit attack, and others similar to it. Any organization that took it upon themselves to engage in the best practices for patch management was likely to have had no problems with MOVEit, but it was still possible to be hit within the first day or two. Thankfully, there is a great deal more that can be done to mitigate the risks of a zero day, such as MOVEit occurring at a given organization.
The problem is few organizations go all out to protect themselves. However, those that do can and should be qualified as the lowest risk. Listed are some additional controls, which, if in place, will further mitigate the risk of a zero day allowing unauthorized access.
- Firewalls – Firewalls are a basic network defensive measure that should be in place to interrogate all internet connections and should be placed on endpoints and between network segments. In the case of MOVEit, this would have helped in circumstances where the server as primarily limited to internal use or to a few organizations, enforced with firewalls. In other circumstances, firewalls can contain most of the damage of a zero day attack.
- Sandboxing – Sandboxing is where certain software is run in a controlled, secured and isolated environment, analogous to a sandbox. This can be done with software that is being tested or that is uncertain. In secure settings, it is always desirable to have a sandbox mentality.
- IPS/IDS – Intrusion Prevention and Intrusion Detection Systems are mature technologies that can monitor IT environments for unseal and suspicions activity. They tend to be very effective, and in the case of MOVEit, it’s likely that this measure would have been enough to detect such unusual and potentially malicious activity. If properly configured, IDS can detect something like a connection, happening from an unusual activity and seeking highly sensitive data. IPS can stop the connection and report it.
- Multiple Layers of Access Control – In the case of MOVEit, most of the servers were connected to the internet and required only logging onto the MOVEit server itself, often with only a login and password. This was never the safest way to set up this kind of connection. Instead, it should have been a more secure process involving multiple layers. Because this software is used for such sensitive files, requiring a separate VPN would make complete sense here and would have prevented the problem.
- Offline Backups – While in the case of MOVEit, the object as not so much to delete data as it was to exfiltrate it, there were also a large number of systems that were locked up or had files deleted or encrypted. Offline backups are a basic general purpose loss control that every organization should have and which will nearly fully mitigate the risk of data loss or downtime, if done properly.
- Data Reduction and Destruction – One of the reasons these attacks are so severe is that organizations retain a great deal of sensitive data. Often, they simply do not have to and it is common for organizations to have far more data on hand than they benefit from. This could have made a powerful difference in reducing the blow of MOVEit. Do dentists need to collect all the social security numbers of their patients? Probably not. Do doctors need to keep the records on file of patients who transferred elsewhere years ago? At the very least, these things can be taken off line, if not used regularly. Keeping a slim inventory of sensitive data is an important risk reduction move few organizations practice.
- Data Leak Prevention, DLP – MOVEit was yet another example of the need for greater use of another general purpose data protection measure: DLP or Data Leak Prevention. It’s one of the most important and under utilized technologies for loss prevention. DLP can sometimes be slightly labor intensive, because it requires tracking down potential false positives, but it’s absolutely essential for high security environments. DLP would have stopped MOVEit, because it would have detected the attempt to exfiltrate unusual amounts of data in unusual ways.
- Internal Only Access – One of the reasons MOVEit was so bad is that most MOVEit servers are available for connection to anyone with an internet connection. Some can even be found by searching Google. This is not a sensible way to run a server that is used for exclusive communications of sensitive material. This is actually common these days, as many organizations use the “web based” services they have available for ease of use. It’s not necessary though. Most of these systems should be kept off the wider internet entirely and only used for internal networks and systems. This is absolutely possible and device and network based security can be enforced a few different ways.
- Network Segmentation – One of the most basic loss control and risk management measures that organizations can take is network segmentation. As the name implies, this means seperating a network into different portions, so that an attacker who gains access to one portion can’t leapfrog to other portions. Most networks are not all that well segmented. In the case of MOVEit, this particular measure would not have made a huge difference, but it could elsewhere. For example, the Solar Winds supply chain attack could have been curtailed through network segmentation.
- Logging – Logging is an important risk control measure. It allows a greater ability to understand what is happening, greater monitoring and response. Logging may not always prevent problems, but it can make them much easier to respond to and can make the damage much less severe.
- Honeypots – A honeypot, and the related concept of honey web are fake decoy servers, files and repositories, intended to be traps for the bad guys to walk into. They can serve both to misdirect attackers an obscure the actual valuable files. Additionally, they can be a powerful detective control. Honeypots would have worked well in the case of MOVEit and can be very effective in other cases. They are barely deployed at all.
- Other General Risk Controls – There are a number of other basic risk controls that could make a big difference here and in the case of other zero day and third party attacks. It really all depends on how the attack goes down and which further vectors are utilized. In many cases, zero day attacks are just the first step in breaking onto a network, so all other measures, such as endpoint protection and keeping systems up to date are valid and could be very useful here.
Working Toward a Mature System
Having insurance companies start working to make sure that their policyholders properly respond to zero day emergencies is a good start, but it’s only a start. For one thing, it does not address the risk that may exist in a third party, such as a payroll provider or MSP which many policyholders may rely on. It also only addresses the problem in those who are insured by that company, and while that is always the company’s primary concern, it is important to realize that every ransomware victim helps sustain the conflagration.
A more mature answer will eventually be to work together, with public sector entities, insurers and soſtware companies working as one to make sure that everyone gets the message and takes the necessary actions, whether disabling or updating the soſtware that has been compromised. This is so critical because zero day emergencies constitute the most severe systemic threat of massive loss across the economy. Without some kind of action, its just a matter of time before an even larger loss hits the US economy due to a zero day exploit.
Working together is also critical because zero day hacks need to be identified as soon as possible. All parties benefit from information sharing agreements and mutual aid, but this remains a very immature area of cyber security. Even the federal government lacks any way of coordinating zero day responses across agencies, resulting in massive losses due to unidentified MOVEit servers at the Justice Department.
In the end, such a system does not need to be expensive. Much of the work can be accomplished by simply having manufacturers of soſtware include an automated feature to allow them to remotely recall soſtware, rendering it inoperable unless patched. It is a bit surprising such systems are not universal to soſtware products, but as things currently stand, most soſtware does not self-enforce patch requirements for even the most critical updates.
Looking Toward the Future
This kind of loss is not acceptable. It’s something that can’t be sustained, and it is stupid to continue to allow society to lose so much, when the answer is right in front of us. Product recall infrastructure clearly needs to be in place. This is made easier by the fact that “software as a service” and automated updates should be able to make it easier to automate software updates.
At present, the biggest hinderance is that software companies do not want to own the problem of how to deal with problems with products. Most software is sold without warrantee or guarantee and the tech companies are loathed to change that. Such practices are far past the point of obsolescence, but historically only the insurance sector has been able to cause the kind of risk management expenditure that other sectors fight.
The problem of not being able to respond to these “zero day” hacks likely will not improve, or will improve only marginally, until there is either insurance sector or regulatory action.
It seems to me that you are contending that the insurance companies are doing a poor job at this? You mention Buffet especially, and would you say he is unique in his dismissiveness?
I’d like to know if you think they can do a better job, then why are they not? Surely, they are losing money here, if they are not well informed, correct?